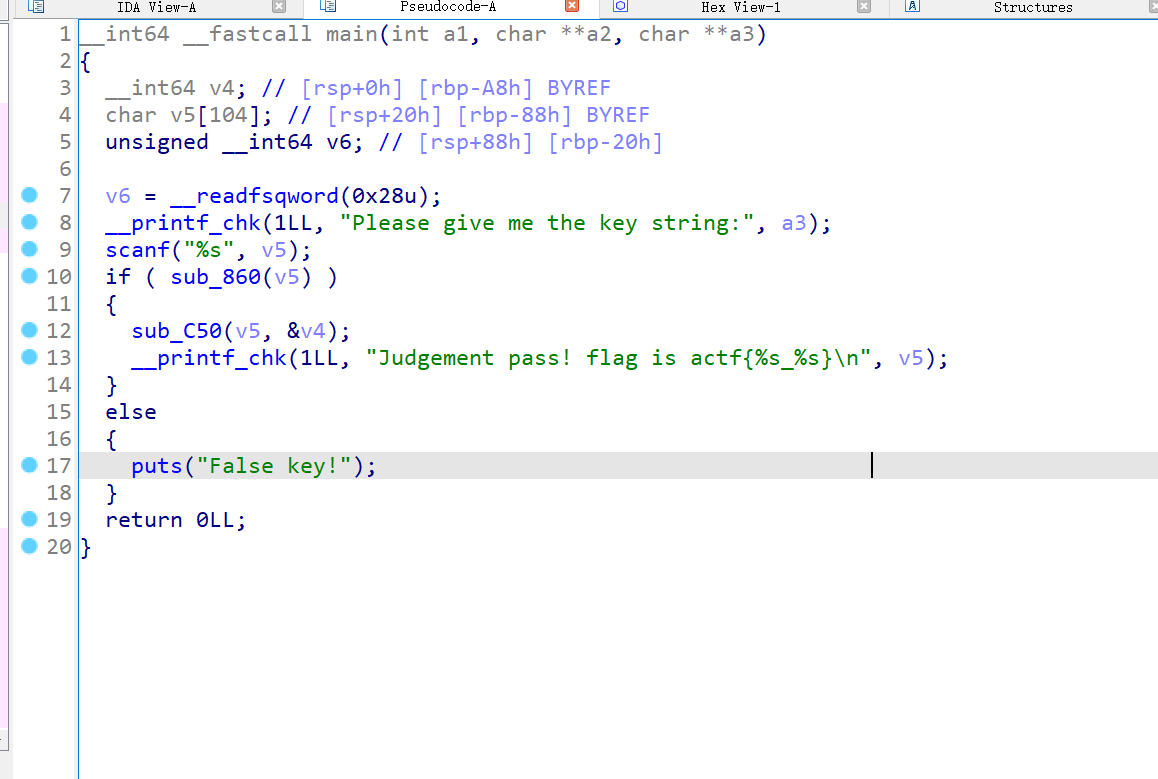
init.pyd模块分析

查看代码,里面有一堆加法,然后传入了init中的方法int()、exit()、exec、m()方法
先对python代码进行简单的简化
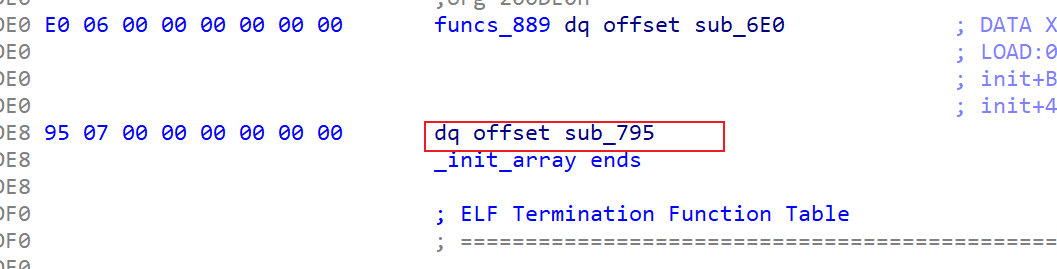
查看一下init.pyd中的方法
pyd_info.py:
import init
x = dir(init)
print("fun b: " ,init.b)
print("fun c: " , init.c)
print("fun e: " , init.e)
print("fun exec: " , init.exec)
print("fun exit: " , init.exit)
print("fun int: " , init.int)
print("fun m: " , init.m)
print("fun p: " , init.p)
help(init)
#result:
'''
fun b: <function b64encode at 0x0000000001671F70>
fun c: <class 'unicorn.unicorn_py3.unicorn.Uc'>
fun e: <unicorn.unicorn_py3.arch.intel.UcIntel object at 0x0000000001522F10>
fun exec: <cyfunction exec at 0x000000000147F5F0>
fun exit: <built-in function eval>
fun int: <class 'str'>
fun m: <class 'operator.methodcaller'>
fun p: <built-in function print>
Help on module init:
NAME
init
FUNCTIONS
a2b_hex(hexstr, /)
Binary data of hexadecimal representation.
hexstr must contain an even number of hex digits (upper or lower case).
This function is also available as "unhexlify()".
exec(x)
exit = eval(source, globals=None, locals=None, /)
Evaluate the given source in the context of globals and locals.
The source may be a string representing a Python expression
or a code object as returned by compile().
The globals must be a dictionary and locals can be any mapping,
defaulting to the current globals and locals.
If only globals is given, locals defaults to it.
i = input(prompt=None, /)
Read a string from standard input. The trailing newline is stripped.
The prompt string, if given, is printed to standard output without a
trailing newline before reading input.
If the user hits EOF (*nix: Ctrl-D, Windows: Ctrl-Z+Return), raise EOFError.
On *nix systems, readline is used if available.
p = print(...)
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
DATA
__test__ = {}
e = <unicorn.unicorn_py3.arch.intel.UcIntel object>
FILE
c:\users\36134\desktop\2025羊城杯\re\re2\chal\init.pyd
*/
'''从help中可以看出
b = b64encode()
p = print(...)
i = input(prompt=None, /)
exit = eval()
e = <unicorn.unicorn_py3.arch.intel.UcIntel object>
m = operator.methodcaller()
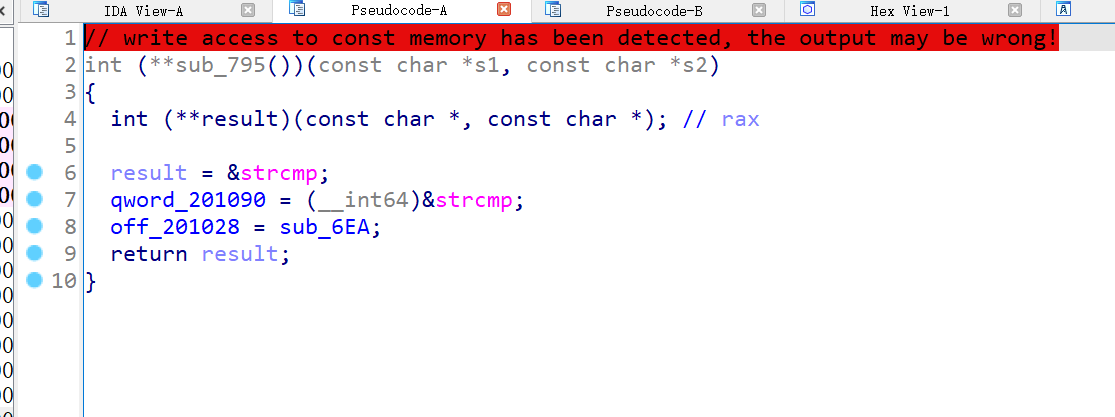
init.int()函数是str类型了,尝试调用这个函数

这个函数实现了加法,返回str类型的和
init.exec()函数暂时看不出来,先放着,根据从init.pyc中得知的信息,将脚本简化
处理plus.py
处理脚本:
import re
with open("plus.py", "r") as f:
data = f.read()
matches = re.findall(r'int\((.*?)\)', data)
solve = []
for i in matches:
if i == '':
solve.append('')
else:
solve.append(eval(i))
for i, match in enumerate(matches):
data = data.replace(f'int({match})', f"'{solve[i]}'")
solve2 = []
matches = re.findall(r'exit\((.*?)\)', data)
for i in matches:
solve2.append(eval(i))
for i, match in enumerate(matches):
data = data.replace(f'exit({match})', f"{solve2[i]}")
data = data.replace(';','\n')
print(data)
处理之后代码:
from init import *
m(exec(30792292888306032),16777216,2097152)(e)
m(exec(30792292888306032),18874368,65536)(e)
m(exec(2018003706771258569829),16777216,exec(2154308209104587365050518702243508477825638429417674506632669006169365944097218288620502508770072595029515733547630393909115142517795439449349606840082096284733042186109675198923974401239556369486310477745337218358380860128987662749468317325542233718690074933730651941880380559453),)(e)
m(exec(2110235738289946063973),44,18939903)(e)
m(exec(2018003706771258569829),18878464, i(exec(520485229507545392928716380743873332979750615584)).encode())(e)
m(exec(2110235738289946063973),39,18878464)(e)
m(exec(2110235738289946063973),43,44)(e)
m(exec(2110235738289946063973),40,7)(e)
m(exec(1871008466716552426100), 16777216, 16777332)(e)
p(exec(1735356260)) if (b(m(exec(7882826979490488676), 18878464, 44)(e)).decode()== exec(636496797464929889819018589958474261894226380884858896837050849823120096559828809884712107801783610237788137002972622711849132377866432975817021)) else p(exec(31084432670685473)) #type:ignore分析e();m();init.exec
查看处理之后的代码,有一个很大的int数值传入了init.exec(),调用这个函数查看

这个函数实现了int2str的功能
自己实现方法:
def int2bytes(n, byteorder: str = "big"):
if n == 0:
return b"\x00"
length = (n.bit_length() + 7) // 8
return n.to_bytes(length, byteorder)接下来分析m() e()方法
m()方法是operator.methodcaller(),这个方法用来创建函数,类似于回调函数
m(x1, x2, x3)(e)等价于e.x1(x2,x3)
e()方法是unicorn.unicorn_py3.arch.intel.UcIntel
Unicorn 是一个基于 QEMU 的CPU 模拟器框架
可以将上面e写成e = unicorn.Uc(UC_ARCH_X86, UC_MODE_64),第一个参数是cpu架构,第二个参数是模式
还原代码
根据上面的分析,就可以将plus.py还原成原本的代码
from unicorn import *
from unicorn.x86_const import *
from operator import methodcaller
from base64 import b64encode as b
e = Uc(UC_ARCH_X86, UC_MODE_64)
e.mem_map(16777216,2097152)
e.mem_map(18874368,65536)
#写入汇编指令
e.mem_write(16777216,b'\xf3\x0f\x1e\xfaUH\x89\xe5H\x89}\xe8\x89u\xe4\x89\xd0\x88E\xe0\xc7E\xfc\x00\x00\x00\x00\xebL\x8bU\xfcH\x8bE\xe8H\x01\xd0\x0f\xb6\x00\x8d\x0c\xc5\x00\x00\x00\x00\x8bU\xfcH\x8bE\xe8H\x01\xd0\x0f\xb6\x002E\xe0\x8d4\x01\x8bU\xfcH\x8bE\xe8H\x01\xd0\x0f\xb6\x00\xc1\xe0\x05\x89\xc1\x8bU\xfcH\x8bE\xe8H\x01\xd0\x8d\x14\x0e\x88\x10\x83E\xfc\x01\x8bE\xfc;E\xe4r\xac\x90\x90]')
e.reg_write(44,18939903)
e.mem_write(18878464,input("[+]input your flag: ").encode())
e.reg_write(39,18878464)
e.reg_write(43,44)
e.reg_write(40,7)
e.emu_start(16777216,16777332)
print("good") if (
b(e.mem_read(18878464,44)).decode()
== "425MvHMxtLqZ3ty3RZkw3mwwulNRjkswbpkDMK+3CDCOtbe6kzAqPyrcEAI="
) else print("no way!")
逐行解析
e = Uc(UC_ARCH_X86, UC_MODE_64)
创建一个 x86-64 的 Unicorn 模拟器实例e.mem_map(16777216,2097152)
在地址0x01000000(十进制 16777216)映射 2MB 内存,作为放置并执行 shellcode 的区域e.mem_map(18874368,65536)
在地址0x01200000(十进制 18874368)映射 64KB 内存,作为数据区e.mem_write(16777216, b'\xf3\x0f\x1e\xfa...')
把一段机器码(长度 116 bytes)写到0x01000000e.reg_write(44,18939903)
给某个寄存器写入常数18939903。代码里并没有以名字注明是哪个寄存器,但其作用是给 shellcode 一个初始化值e.mem_write(18878464,input("[+]input your flag: ").encode())
把用户的输入写到地址18878464这个地址和上面 data 区的基址有关系:18878464 - 18874368 = 4096 = 0x1000所以输入被写入 data 区内偏移
0x1000的位置(也就是0x01201000)三个
reg_write:e.reg_write(39,18878464) e.reg_write(43,44) e.reg_write(40,7)这三行把函数参数或工作寄存器设为:
- 一个指针(指向你放入的输入:
18878464) - 一个长度 / 计数(
44) - 另一个常数(
7)
在 x86-64 的调用约定里,整数参数通常通过 RDI/RSI/RDX/RCX/… 传递 这里使用具体的寄存器编号来配合 shellcode 读取参数
- 一个指针(指向你放入的输入:
e.emu_start(16777216,16777332)
开始在0x01000000执行,直到0x01000000 + 116,执行过程中,shellcode 会读取/写入 data 区最后比较:
b(e.mem_read(18878464,44)).decode() == "425MvHMxtLqZ3ty3RZkw3mwwulNRjkswbpkDMK+3CDCOtbe6kzAqPyrcEAI="先对处理后的 44 字节用 base64编码得到字符串,再和enc进行比较
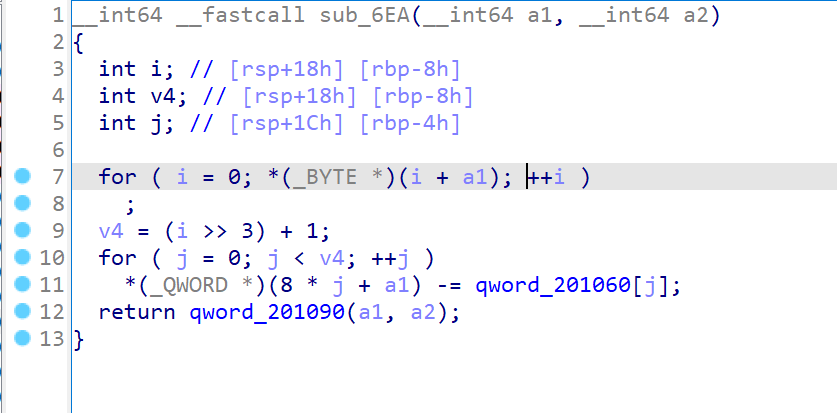
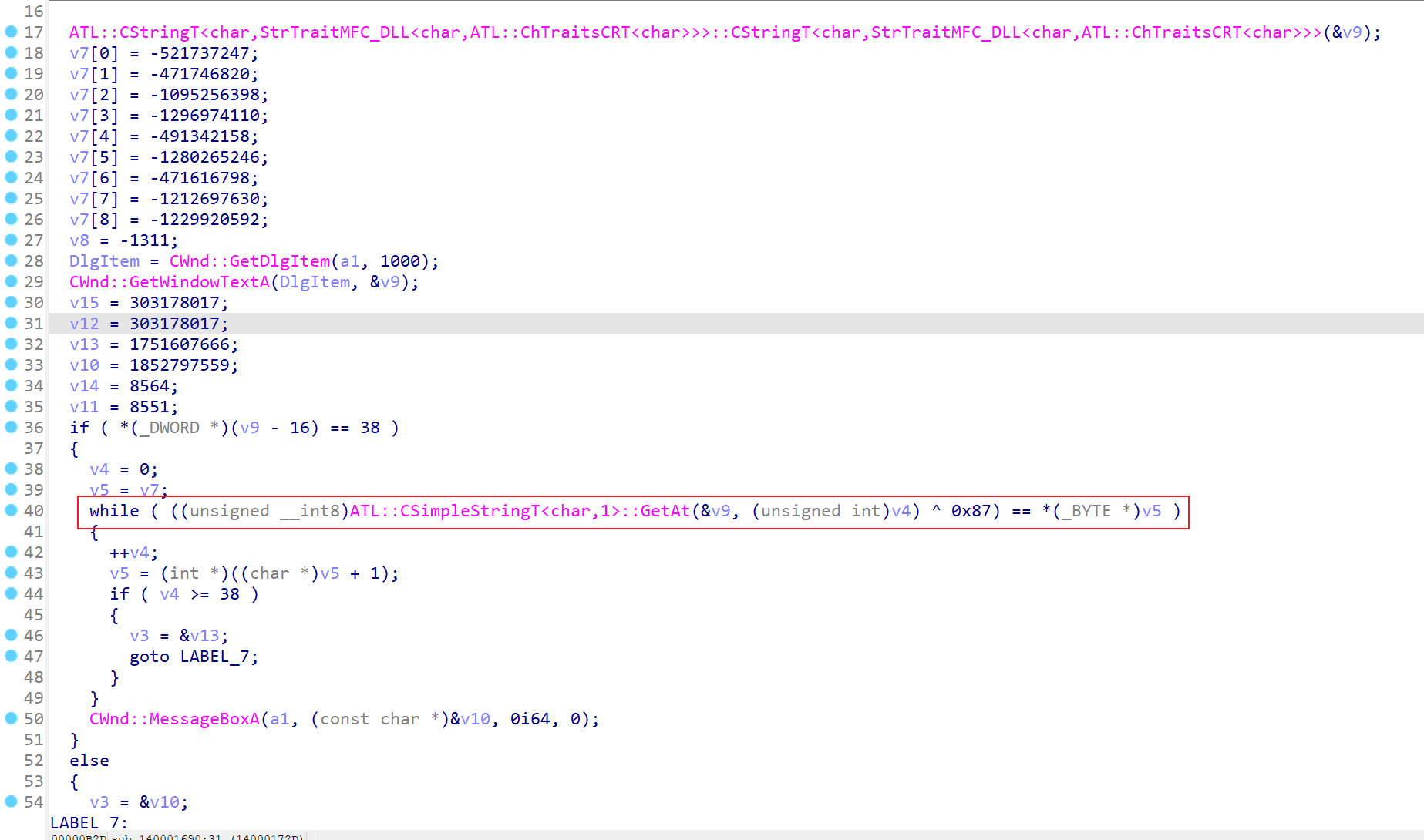
汇编分析

将汇编指令以二进制保存,使用ida打开分析,稍微处理一下数据类型和变量名

这里使用异或和乘法进行运算,因为除法不能直接逆运算,所以要爆破
Exp
写脚本爆破flag
import base64
enc = base64.b64decode("425MvHMxtLqZ3ty3RZkw3mwwulNRjkswbpkDMK+3CDCOtbe6kzAqPyrcEAI=")
flag = ''
for i in range(44):
for j in range(32,127):
if ((8 * j) + (7 ^ j) + (32 * j)) &0xff == enc[i]:
flag += chr(j)
break
print(flag)
#result
#DASCTF{un1c0rn_1s_u4fal_And_h0w_ab0ut_exec?}